在之前幾天,介紹缺失值的處理(Handling Missing Data)、分層索引(Hierarchical Indexing),今天要來介紹資料組合(Combining Datasets)及分組與聚合(Aggregation and Grouping)
imprt numpy as np
import pandas as pd
數據的蒐集來源來自不同地方,而有時候在做資料統計、資料分析時,就需要將資料就行連接、合併。而在pandas中提供concat函數來簡單連接資料。
x = [[1, 2],
[3, 4]]
np.concatenate([x, x], axis=1)
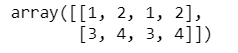
ser1 = pd.Series(['A', 'B', 'C'], index=[1, 2, 3])
ser2 = pd.Series(['D', 'E', 'F'], index=[4, 5, 6])
pd.concat([ser1, ser2])

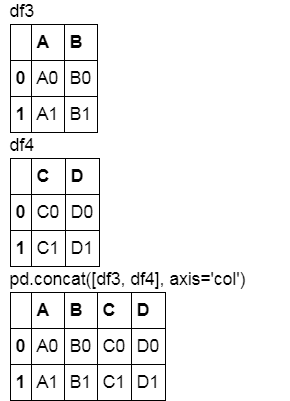
df3 = make_df('AB', [0, 1])
df4 = make_df('CD', [0, 1])
display('df3', 'df4', "pd.concat([df3, df4], axis='col')")
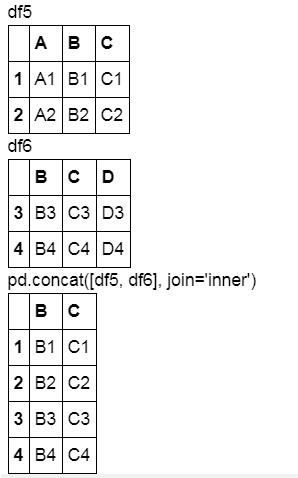
display('df5', 'df6',"pd.concat([df5, df6], join='inner')")
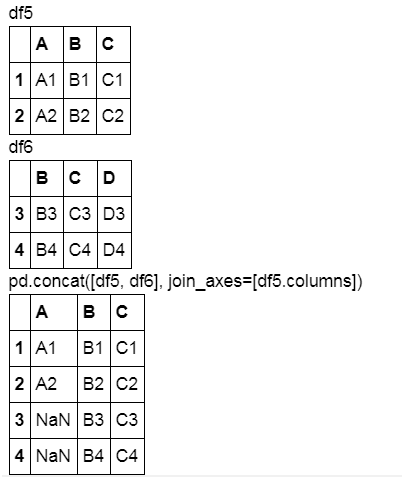
display('df5', 'df6', "pd.concat([df5, df6], join_axes=[df5.columns])")
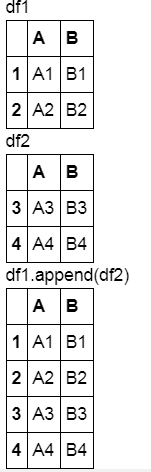
2.append()
append方法不會修改原始對象,而是使用組合數據來創建新的對象。
display('df1', 'df2', 'df1.append(df2)')
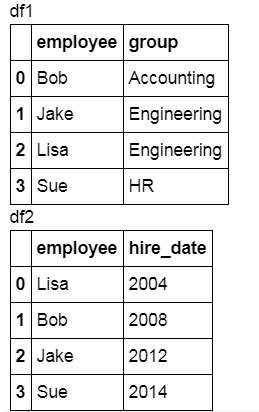
df1 = pd.DataFrame({'employee': ['Bob', 'Jake', 'Lisa', 'Sue'],
'group': ['Accounting', 'Engineering', 'Engineering', 'HR']})
df2 = pd.DataFrame({'employee': ['Lisa', 'Bob', 'Jake', 'Sue'],
'hire_date': [2004, 2008, 2012, 2014]})
display('df1', 'df2')
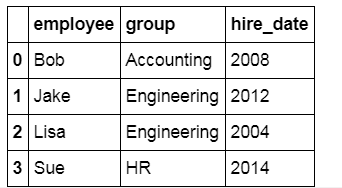
df3 = pd.merge(df1, df2)
df3
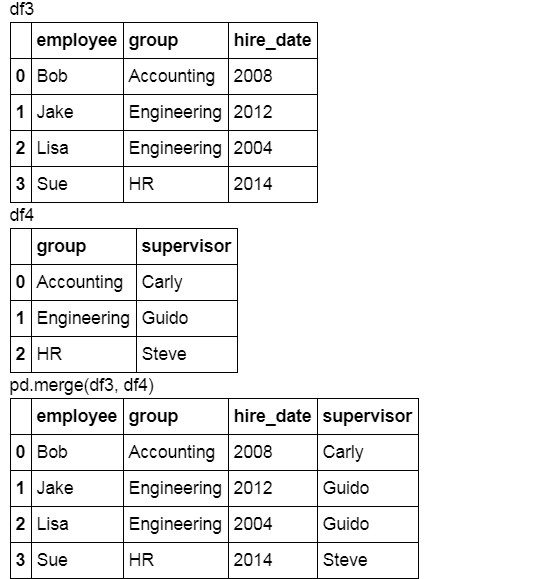
df4 = pd.DataFrame({'group': ['Accounting', 'Engineering', 'HR'],
'supervisor': ['Carly', 'Guido', 'Steve']})
display('df3', 'df4', 'pd.merge(df3, df4)')
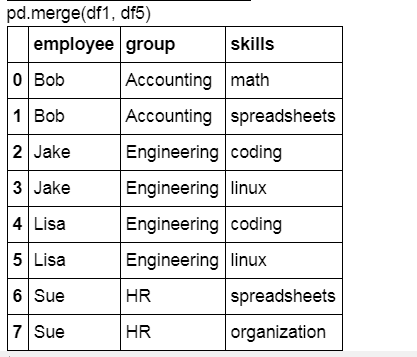
df5 = pd.DataFrame({'group': ['Accounting', 'Accounting',
'Engineering', 'Engineering', 'HR', 'HR'],
'skills': ['math', 'spreadsheets', 'coding', 'linux',
'spreadsheets', 'organization']})
display("pd.merge(df1, df5)")
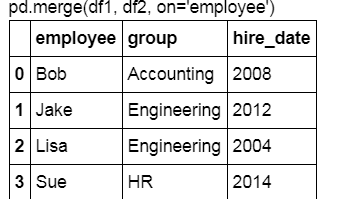
display('df1', 'df2', "pd.merge(df1, df2, on='employee')")
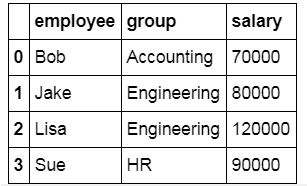
df3 = pd.DataFrame({'name': ['Bob', 'Jake', 'Lisa', 'Sue'],
'salary': [70000, 80000, 120000, 90000]})
display('df1', 'df3', 'pd.merge(df1, df3, left_on="employee", right_on="name").drop('name', axis=1)')
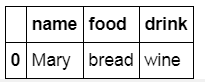
df6 = pd.DataFrame({'name': ['Peter', 'Paul', 'Mary'],
'food': ['fish', 'beans', 'bread']},
columns=['name', 'food'])
df7 = pd.DataFrame({'name': ['Mary', 'Joseph'],
'drink': ['wine', 'beer']},
columns=['name', 'drink'])
display('df6', 'df7', 'pd.merge(df6, df7, how='inner)')